When does traditional classification algorithm fail?
One of the most intriguing Machine Learning problems that I have come across was during my 3rd year in the college where a startup named Quantta Analytics presented us with the problem statement about a power distribution company which had observed a significant loss of revenue over a period of time. The loss in revenue was mainly becuase of possible power theft by malicious consumers. The power company resorted to periodic vigilance of customers by sampling and creating a database of only the fraudulent customers to curb this practice. The company wanted the vigilance process to be more robust and effective. Hence, the objective of the problem statement was to deploy a machine learning algorithm to provide a list of customers who are likely to commit fraud. So the problem was effectively a classification problem (with a catch!) where given the attributes of a customer, we had to predict where it is likely to commit the electricity theft or not.
In order to appreciate the problem statement, let us first have the review of the well-known famous classification algorithms. Classification problems try to solve the two or multi-class situation. The goal is to distinguish test data between a number of classes, using training data which has samples from all the possible classes and training data has reasonable level of balance between the various classes. Now the question that arise is - At what levels of imbalance does the use of traditional classifiers becomes futile?
This paper has made observation by conducting experiments on various datasets from the UCI repository, and monitoring the performance of the traditional classifiers. I am listing down the most important observations stated in the paper:
-
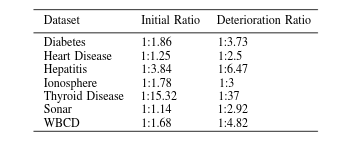
The performance of the traditional classifiers start to decline when the imbalance between output classes increase and the decline becomes prominent at the ratio 1:2.8.
-
At the ratio 1:10, the performance is so poor for traditional classifiers that it can no longer be trusted.
Figure below shows the initial ratio of the classes present in UCI dataset and the ratio at which the performance of the binary classifiers starts to deteriorate.
Now the questions that arise are - what if we have the training data which has imbalance between the classes or data only from one class? Why do we need to study such case? And are there any situations where such data is available?
To answer the latter first, yes there are plenty of situations where we have the data from only one class. Consider a case of a nuclear power plant. We have the measurement of the plant conditions such as temperature, reaction rate when the plant is in working condition. Is it possible to get such measurements in case of an accident? No. Now, if we want to predict the possible scenario of the breakdown of the plant. From the above observations it is sure that the traditional classification algorithms will not perform well. Some other cases are:
-
Detection of oil spill
-
In computational biology to predict microRNA gene target
There are 2 methods to tackle the case when we have data from only one class:
-
The first method is an obvious approach to generate an artificial second class and proceed with traditional classification algorithms.
-
The second one is to modify the existing classification algoriths to learn on the data from only one class. These algorithms are called "one-class classfication algorithms" and include one-class SVM, One-Class K-Means, One-Class K-Nearest Neighbor, and One-Class Gaussian.
I will be elaborating on the above two methods in my next blog post. Thank you very much for making it this far.