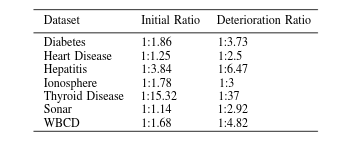
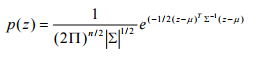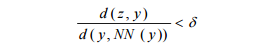The Unlikely Programmer: My Journey from Computer Illiteracy to Presenting at Massachusetts Institute of Technology (MIT)
Only a select few of my closest friends are aware of my journey from computer illiteracy to becoming a computer scientist. Recently, my very dear friend and my first mentor, Anshit Mandloi, encouraged me to pen a blog post about my progression—how I managed to transcend my lack of knowledge in computers and present my work at the Massachusetts Institute of Technology (MIT) within four years.
The purpose of sharing this deeply personal account is to provide inspiration to individuals who, like me, hail from similar backgrounds and may be grappling with doubts about their potential to navigate the vast landscape of technology. Through this blog post, my hope is to kindle the spark of possibility that with determination, the most remarkable transformations can be well within our reach.
The Beginnings
I come from a small town situated in one of the less developed regions of North India. Hailing from a family of eight, my father shouldered the role of the sole provider. In such circumstances, pursuing quality education proved to be an uphill battle, rendering the idea of having a computer at home an impossible dream. Hence, my exposure to computers was limited to the few sessions we had during our high school curriculum.
However, destiny had its designs, I managed to emerge successful in the IIT-JEE exam (an exam with an acceptance rate of 1%). This paved the way for my academic journey, leading me to opt for the study of Mathematics and Computer Science at the Indian Institute of Technology, Kharagpur.
The Challenges
IIT Kharagpur marked the beginning of a grueling trial. I very vividly recall my initial encounter with a black terminal screen, on a Sun Microsystems Unix machine, during my first C programming lab. Panic washed over me as I found myself completely clueless about navigating this challenge. For the first 30 minutes, I remained immobilized and it was only after summoning the courage to approach one of the teaching assistants and confess my utter inexperience with the computers that I got myself started. This was just the beginning of a huge challenge that lay ahead. As the clock ticked, I mustered the determination to engage with the terminal, but the initial hours only yielded a mere 2-3 lines of code. Some of my classmates, in stark contrast, efficiently accomplished the task within half an hour. Attending lectures with unwavering attention became my mantra, though comprehending the intricate subject posed a trial in itself. Even trying to read books like "The C Programming Language," authored by one of the language's creators, failed to yield substantial success.
It was, undoubtedly, a humbling experience to transition from being one of the top performers to grappling with a newfound identity as one of the class's less accomplished individuals—especially amidst peers who had participated in international programming olympiads.
What accompanied these challenges was not merely technical, but a roller-coaster of emotions. Frustration set in, and self-doubt crept in as I questioned my capability to bridge the gap between my knowledge and the complex world of programming.
The Journey
Over time, my determination to grasp the unfamiliar and uncover the secrets of programming only grew stronger. I began with a book that my professors discouraged but I could understand it on my own - "Let Us C" by Yashwant Kanetkar. My evenings were dedicated to the library, reading a page or two and writing down notes. Every week, I spent all my allotted lab time attempting assignments, often ending in failure.
It was during these moments that I found invaluable friends and mentors who recognized my need for help. My wingmates, Anshit Mandloi, and Naman Mitruka, were instrumental in my journey. They patiently listened, clarified my doubts, and even guided me through basic programming exercises.
In my second year at the university, I met Harsh Gupta, who was my batchmate, and he played a pivotal role in my growth as a programmer. His willingness to lend a helping hand on numerous occasions marked a turning point in my journey. He generously shared his knowledge, ensuring I grasped complex concepts and tackled intricate problems with confidence.
After three years of taking various courses, and participating in hackathons (with mostly failures), my confidence as a programmer began to bloom. It was finally time to put my skills to the test in the real world.
MIT
My aspiration was to become a part of the esteemed Google Summer of Code program. In my initial attempt at the end of my third year at university, I faced rejection. I tried the following year and my effort bore fruit. I spent the summer of 2016 contributing to the Julia Programming Language, specifically adding support for optimization with complex numbers in their Convex.jl library.
It was during this summer, an unexpected invitation arrived: I was asked to speak about my work at JuliaCon'16, hosted at MIT in Boston. Visiting MIT had always been a dream, one I thought might forever remain unfulfilled, let alone being invited as a speaker at a conference there. It felt as though all my struggles and hard work had unknowingly paved the path to MIT. This experience to this day still stands as one of the proudest moments of my life, reinforcing the belief that, regardless of where one begins, one can achieve things beyond their wildest dreams.
As a concluding note, I'll share the link to the talk I presented. Please bear with any imperfections in my English, as I also grappled with it during my programming journey – a story for another time :)
I hope this blog post has left you feeling inspired. I eagerly await your feedback and hope to hear your thoughts and stories as well!

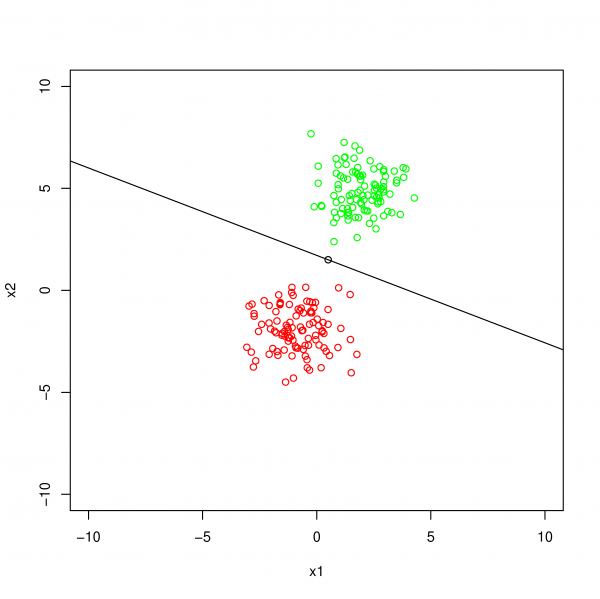 Binary Classification Hyperplane
Binary Classification Hyperplane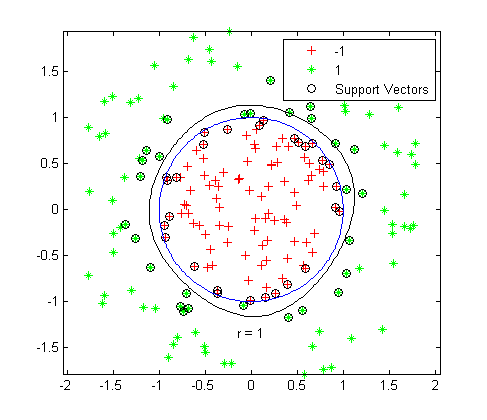 One-Class Classification Boundary
One-Class Classification Boundary